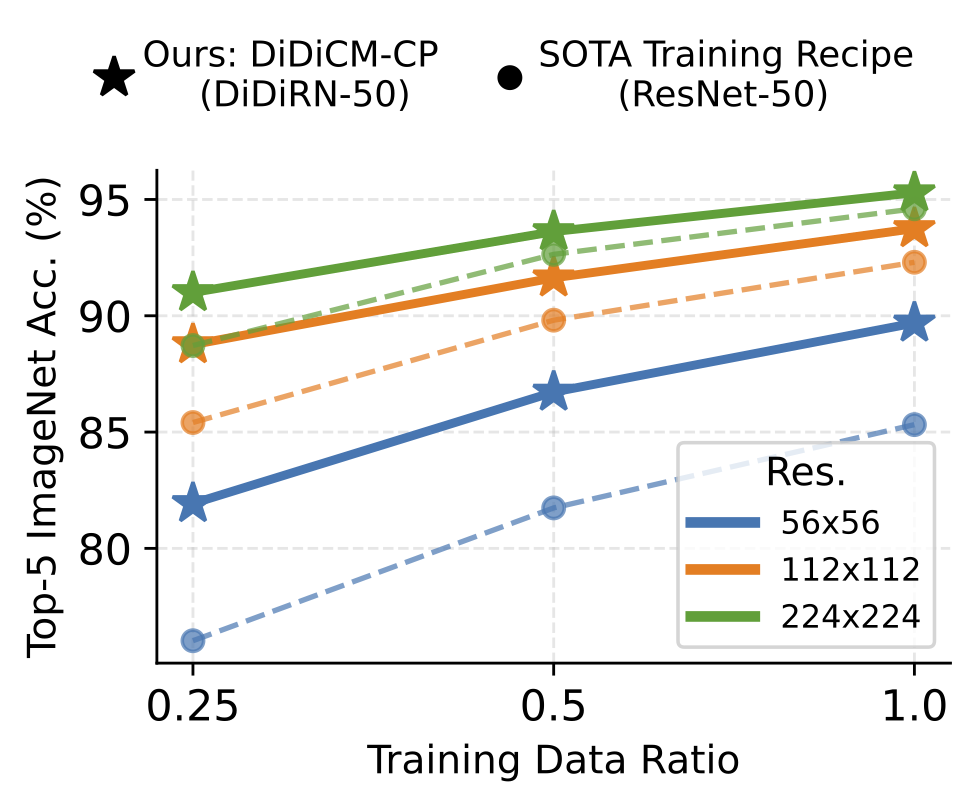
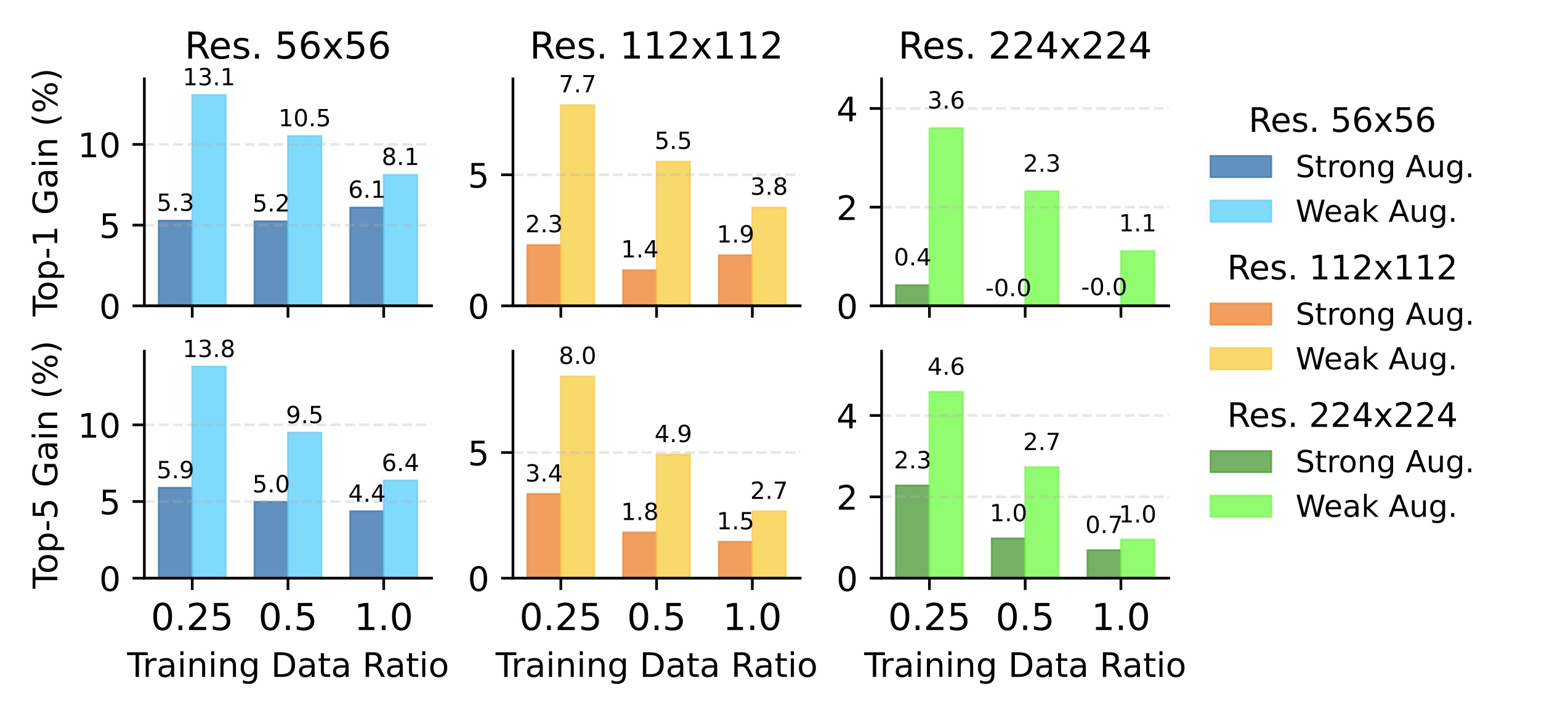
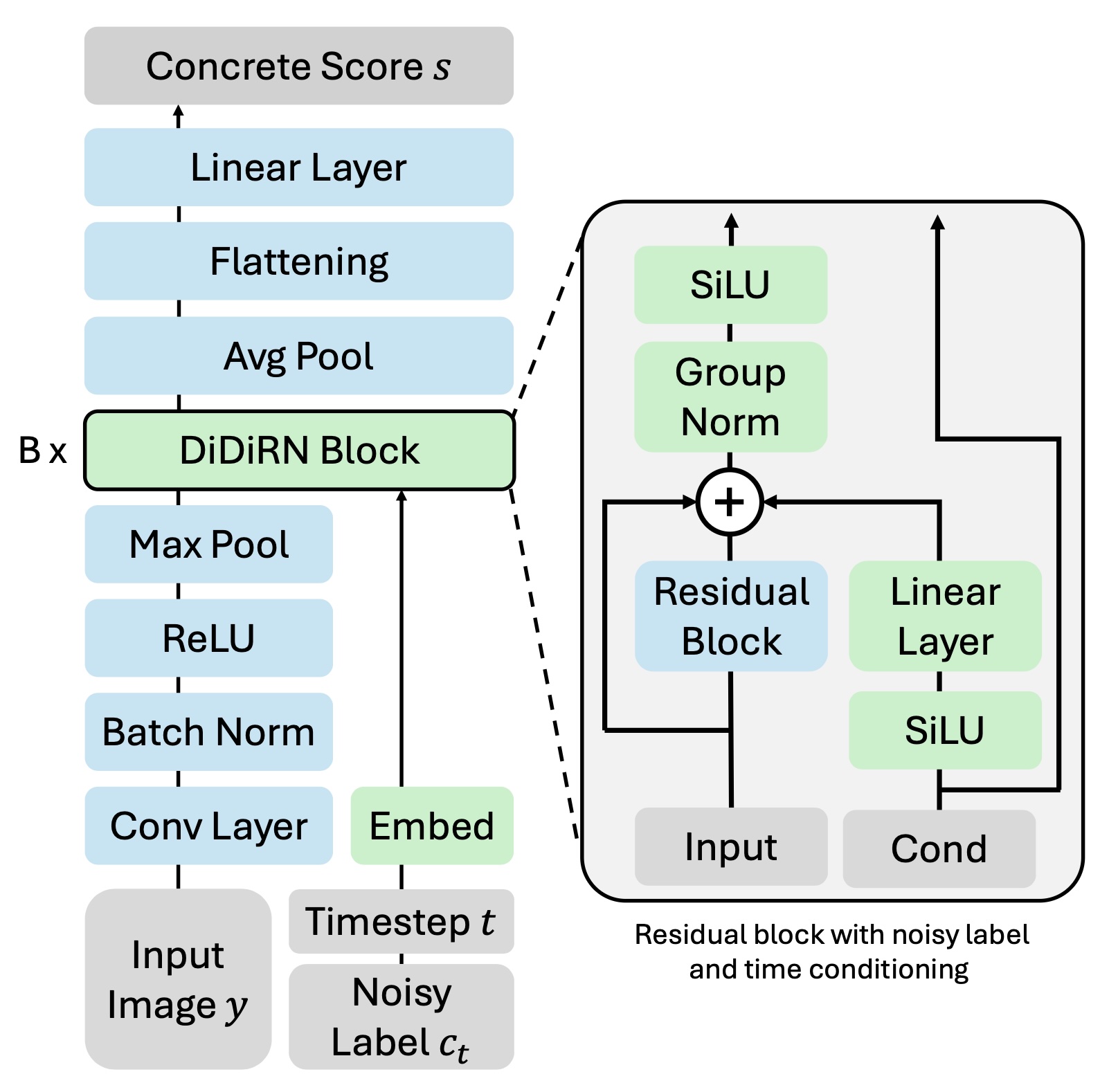
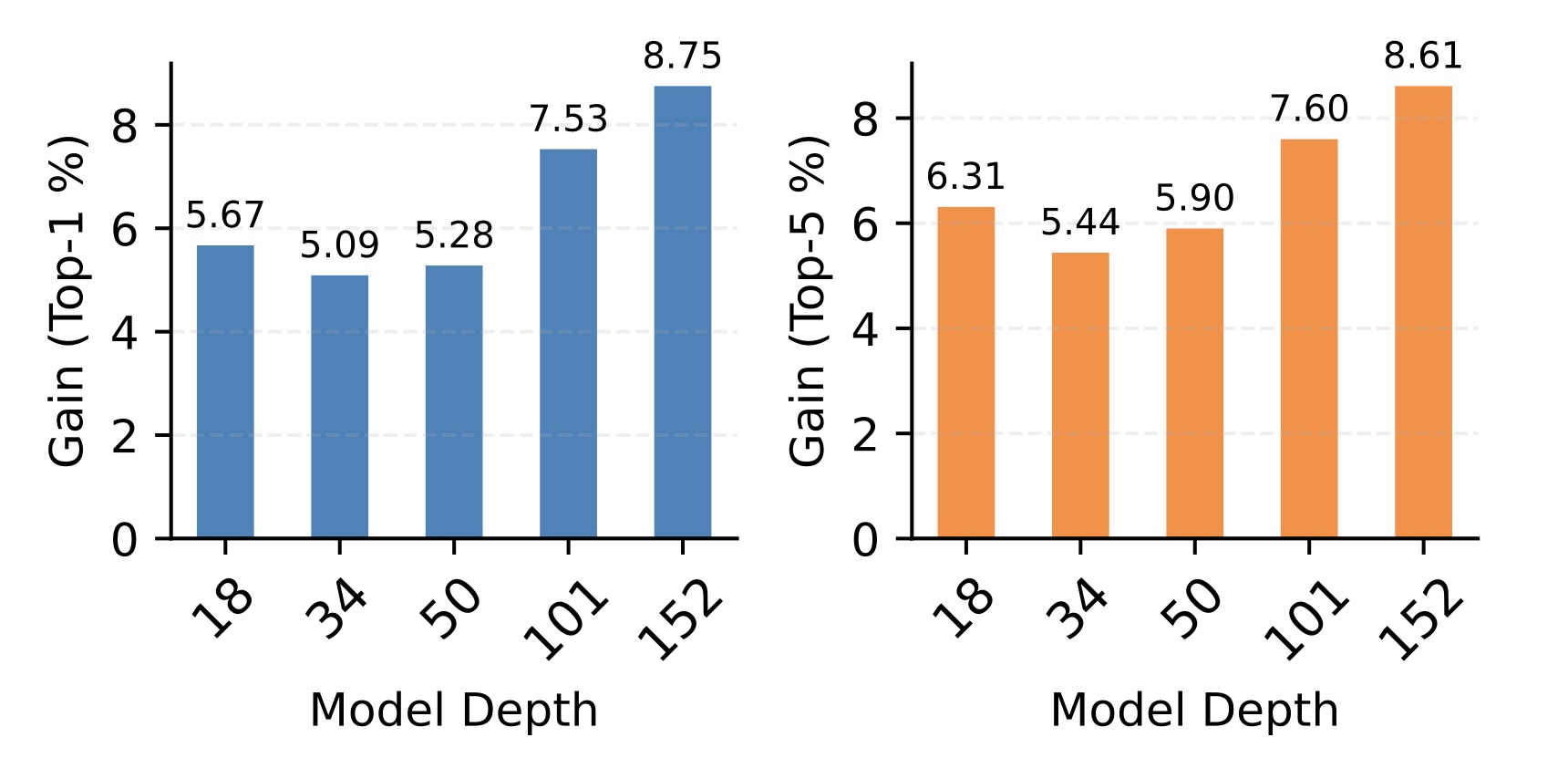
Despite the advancements in architectural designs and capacity of modern classification models, the fundamental probabilistic formulation of the classification task has remained largely static, primarily relying on discriminative models that learn a direct mapping from an input image to a categorical distribution via the softmax operator. While this paradigm has proven exceptionally effective in large-scale datasets with high-quality imagery, it exhibits significant fragility when confronted with the high-uncertainty conditions inherent in real-world applications, such as significant image corruption, low resolution, or severely limited training data. The inherent limitation of standard discriminative approaches lies in their objective function, which often disregards the stochastic nature of the transformation from a clean latent signal to a corrupted observation, thereby introducing unavoidable biases into the optimization process.
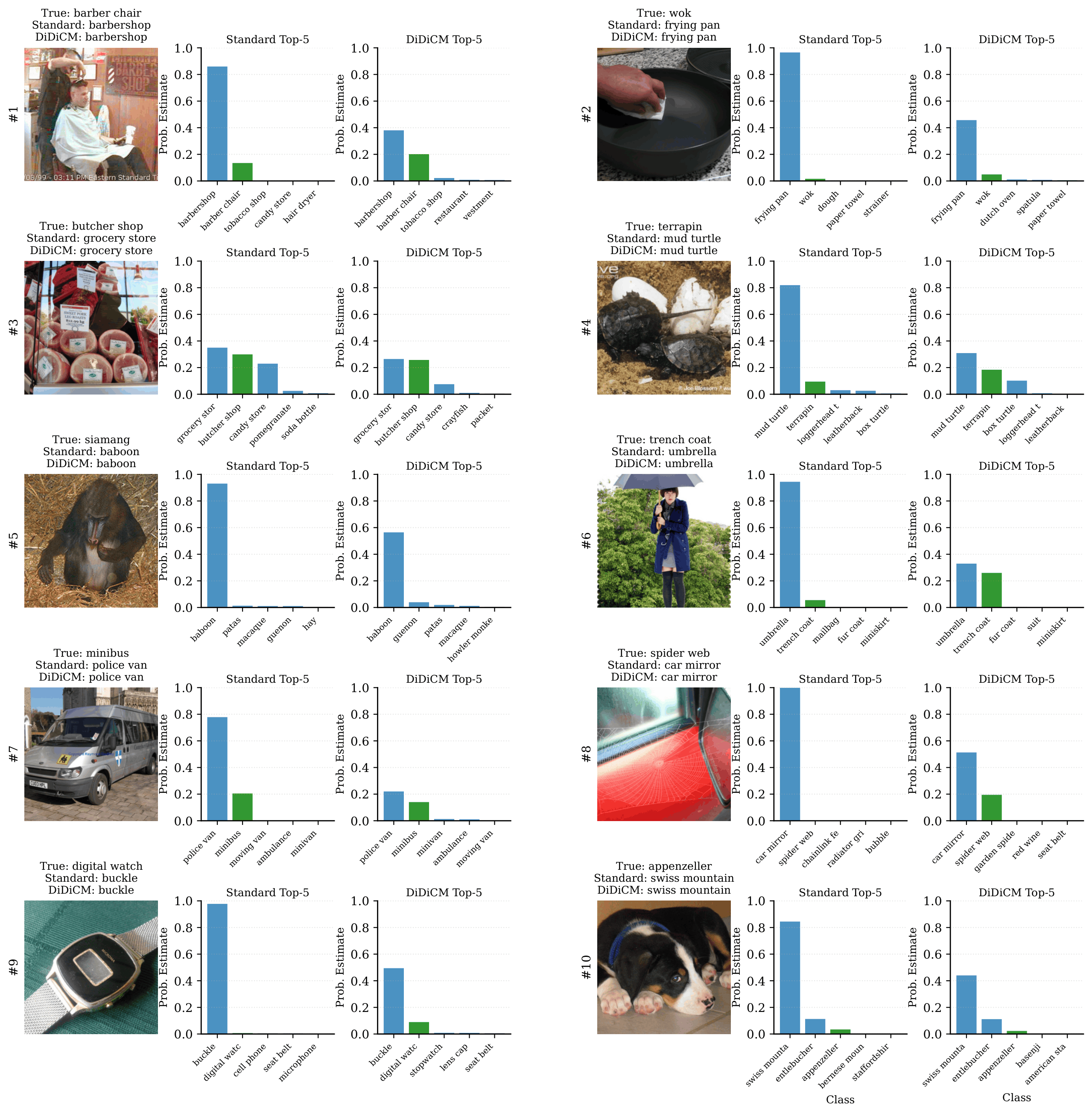
To address these systemic vulnerabilities, DiDiCM introduces a transformative framework that reformulates image classification as an iterative generative diffusion process within the discrete space of class labels. DiDiCM leverages the principles of continuous-time discrete diffusion to model the posterior distribution of class labels conditioned on the input image. By simulating a reverse diffusion process directly in the label domain, this approach enables a more analytically grounded and robust estimation of the label posterior, particularly in scenarios where the input signal is too degraded for a single-pass classifier to resolve. This methodology marks a departure from previous diffusion-based classification attempts that relied on the computationally expensive reconstruction of full images, instead focusing on the tractability of the discrete label space to achieve superior accuracy and efficiency.
Let $\rvx$ be a random vector, and let $\rvy = h(\rvx)$ be an observation of $\rvx$, where $h$ is an unknown, possibly stochastic and non-invertible function.
Note that $h$ may also be the identity function, in which case $\rvy = \rvx$.
Let $\rc \in \{ 1, \dots, K \}$ be a random class label assigned to $\rvx$, where $\rc$ lives in a finite discrete space of $K$ class labels.
In this work, our goal is to model $P(\rc|\rvy) \in \R^K$ with a parameterized model $p_\theta(\rc|\rvy) \approx P(\rc|\rvy)$.
Building on current research in discrete diffusion, we address this classification task within a continuous-time diffusion framework, where the target distribution of interest is the posterior, $P(c|y)$.
Mathematical Formulation of the Forward Diffusion Process
The DiDiCM framework defines the forward diffusion process across a continuous time interval $t \in [0,1]$ as the evolution of a noisy distribution $q(\rc_t|\rvy)$. This evolution is characterized by a linear ordinary differential equation (ODE) that describes a continuous-time Markov process :
$$\frac{dq(\rc_t|\rvy)}{dt} = R_t \cdot q(\rc_t|\rvy)$$
In the above equation, $R_t$ represents the transition rate matrix at time $t$. We adopt a uniform transition rate matrix, $R_t := \sigma_t (11^T - KI)$, where $\sigma_t$ is a strictly decreasing noise schedule. This matrix defines the rate at which the class label transitions to any other random class label within the finite discrete space of $K$ classes. The choice of a uniform matrix implies that as the diffusion process proceeds toward $t=1$, the distribution $q(\rc_1|\rvy)$ converges to a uniform distribution over all class labels, representing a state of maximum entropy or total noise.
The transition rate matrix $R_t$ can be decomposed using its eigenvectors $U$ and eigenvalues $\Lambda$. Given the uniform structure of the rates, these components are mathematically tractable, allowing for a closed-form solution to the forward process at any arbitrary time $t$ :
$$q(\rc_t|\rvy) = U \exp(\bar{\sigma}_t \Lambda) U^{-1} \cdot q(\rc_0|\rvy)$$
Here, $\bar{\sigma}_t=\int_0^t \sigma_s ds$ denotes the integrated noise applied up to time $t$. For a log-linear noise schedule, $\sigma_t := a b^t \log b$, the total noise $\bar{\sigma}_t$ also admits a closed-form solution, which facilitates efficient training by allowing the model to sample any noise level $t$ without simulating the entire Markov chain.
The Reverse Process and the Concrete Score
The core objective of DiDiCM is to learn a reverse process that can recover the clean posterior distribution from the uniform noise. This is achieved by defining a reverse ODE that flows from $t=1$ back to $t=0$.
The reverse process models the evolution of the estimated posterior $p(\rc_{1-t}|\rvy)$ as time $t$ progresses from 0 to 1 (corresponding to the original time $t$ moving from 1 to 0). The reverse ODE is defined as:
$$\frac{dp(\rc_{1-t}|\rvy)}{dt} = \bar{R}_{1-t} \cdot p(\rc_{1-t}|\rvy)$$
The starting point for this process is $p(\rc_1|\rvy) = \mathcal{U}(\{1, \dots, K\})$, representing the uniform distribution where no information about the image category is yet known.
To solve the reverse ODE, the model must know the reverse transition matrix $\bar{R}_t$. In discrete diffusion, this matrix is fundamentally linked to the "Concrete Score" $S_t$
(Meng, 2022,
Lou, 2023). The Concrete Score is defined as the matrix of ratios between the noisy marginal probabilities of the label states:
$$S_t(i, j; \rvy) := \frac{q(\rc_t=i|\rvy)}{q(\rc_t=j|\rvy)}$$
A neural network $s_\theta(y, j, t)$ is trained to predict these ratios for all possible classes $i$ given the input image $y$, a noisy label $j$, and the current time $t$. Unlike continuous diffusion where the score is a vector of gradients, the discrete score is a vector of probability ratios. This shift is significant because it allows the model to capture the relative likelihood of every class at every step of the denoising process.
Once the scoring model provides the estimated scores $S_t$, the reverse transition matrix is constructed as:$$\bar{R}_t := S_t \odot R_t - \text{diag}(1^T (S_t \odot R_t))$$where $\odot$ is the Hadamard (element-wise) product. This construction essentially "tilts" the forward noise matrix $R_t$ in the direction of the true data distribution. By following this reverse ODE, the uniform distribution is gradually reshaped into the target posterior distribution $P(c|y)$.
The Training Objective: Score Entropy Loss
Standard score matching techniques often struggle in discrete spaces due to the intractability of the normalizing constants. Score Entropy avoids this by utilizing a loss that is functionally equivalent to the cross-entropy between the true score and the predicted score, weighted by the noise schedule. For a sampled time $t$ and a noisy label $j \sim q(\rc_t|\rvy)$, the loss is:
$$\mathcal{L}_{\text{DiDiCM}}(\theta) := \mathbb{E}_{t, y, j} \left[ \bar{\sigma}_t \sum_{i=1}^{K} \left( \hat{s}_i - s_i \log \hat{s}_i + A(s_i) \right) \right]$$
In this equation, $s_i$ is the true ratio $q(\rc_t=i|\rvy)/q(\rc_t=j|\rvy)$, $\hat{s}_i$ is the prediction $[s_\theta(\rvy, j, t)]_i$, and $A(s_i)$ is a constant term that does not depend on the model parameters $\theta$. The factor $\bar{\sigma}_t$ acts as a noise-dependent weighting, emphasizing steps where the noise is most informative for the denoising process.
Reversal Simulation Approaches: DiDiCM-CP and DiDiCM-CL
The transition from a continuous-time ODE to a practical inference algorithm requires a discretization strategy. We propose two distinct methods for simulating the reverse process, each offering different trade-offs in terms of computation and memory.
DiDiCM-CP (Class Probabilities)
The CP variant operates directly on the vector of class probabilities. It treats the reverse process as a deterministic evolution of the distribution $p_t \in \mathbb{R}^K$.
- Mechanism: At each time step $t$, the model predicts the score for a representative state (often the most likely class or an average) and updates the entire probability vector using the matrix-vector product $(I + \bar{R}_t \Delta t) p_t$.
- Performance Insight: This method is highly stable and deterministic. It provides a smooth "refining" of the probabilities, which is particularly effective for high-uncertainty tasks where the posterior might be multimodal.
- Complexity Cost: The primary drawback is the $O(K^2)$ memory consumption per step due to the transition matrix $\bar{R}_t$. For ImageNet-1K, this is manageable, but for datasets with tens of thousands of classes, it may become a bottleneck.
DiDiCM-CL (Class Labels)
The CL variant takes a stochastic approach, simulating the trajectory of a discrete label $\rc_t$ rather than a probability vector.
- Mechanism: At each step, the model queries the score for the current discrete label $\rc_t$. It then uses the transition probabilities defined by $\bar{R}_t$ to sample a new label $\rc_{t-\Delta t}$.
- Performance Insight: This variant is extremely memory-efficient, as it only ever deals with a single label at a time. To estimate the final posterior distribution, one can run multiple parallel simulations (sampling) and aggregate the results.
- Complexity Cost: While each step requires $O(K)$ memory, the need for multiple sampling chains to reduce variance can increase the overall computational cost.
| Sampler Variant |
State Space |
Computation |
Memory |
Accuracy/Stability |
| DiDiCM-CP |
Continuous (Probabilities) |
Fast |
High |
Very High |
| DiDiCM-CL |
Discrete (Labels) |
Slow |
Low |
Moderate/High |